반응형

DDL 개념과 종류
| DDL 개념 데이터베이스에서 DDL은 '데이터 정의어'라고 부른다. 데이터를 담는 '표(Table)'라는 틀 자체를 만들거나 바꾸거나 없애는 명령어들이다 DDL 종류 1. CREATE(생성): 새로운 테이블(표)를 처음으로 만드는 것 * 테이블(표)의 이름을 무엇으로 할지, 컬럼은 몇 개로 할지 등 정해서 아예없던 상태에서 표를 새로 만든다 2. ALTER(수정): 이미 만들어진 표의 구조를 바꾸는 것 * 테이블(표)에 새로운 칸을 추가, 필요 없는 칸을 삭제 하는 등에 사용 3. DROP(삭제): 테이블(표)을 통째로 없애버리는 것 * 표 안에 들어있던 모든 데이터와, 표의 틀(구조)까지 완전히 삭제함 4. RENAME(이름 변경): 테이블(표)의 이름을 바꾸는 것 5. TRUNCATE(비우기): 표의 틀을 남겨두고 내용물(데이터)만 싹 다 지우는 것 |
테이블 생성과 삭제
| 테이블 생성 CREATE TABLE 테이블 ( 컬럼 컬럼의 데이터_타입 [DEFAULT 값] [컬럼 레벨 제약조건], ...... [테이블 레벨 제약조건], ..... ); 테이블 삭제 DROP TABLE 테이블 [CASCADE CONSTRAINT]; * 회사에서 운영하고 있는 데이터베이스에서 테이블을 삭제하지는 않음 테이블을 삭제한 휴지통을 비우는 명령어 PURGE RECYCLEBIN; |
테이블 생성 규칙
| 1. 문자로 시작함 2. 30자 이내 3. 영문, 숫자, _, $, #을 사용 * 한글 사용은 가능하지만 되도록 사용하지 않는 것이 좋음 4. 테이블의 이름은 동일한 유저 안에서 유일해야 함 5. 예약어는 사용이 불가능함 ---> EX. 예약어:select , from, where 6. 대소문자 구별하지 않음 * 생성할 때 사용한 문자와 관계없이 모든 이름은 대문자로 정의됨 |
컬럼의 데이터 타입 (컬럼에 어떤 데이터 타입을 저장할 수 있는지)
| 가장 많이 사용하는 데이터 타입 1. VARCHAR2(n): 가변 길이 문자 타입(1 < n < 4000 byte) - VARCHAR2(n)에서 n은 글자 수가 아니라, 그 안에 들어갈 글자들의 '무게 합계(바이트)'가 최대 n만큼이다 - 최대 저장할 수 있는게 1바이트 이상 ~ 4000바이트까지 저장 가능 ex. varchar2(10), char(10) vachar2는 5바이트를 사용하면 5바이트만 사용되지만 char는 5바이트를 사용해도 10바이트가 사용된다 2. NUMBER(n,p) - 숫자 타입, n은 전체 자리수이고 p는 소수점 이하 자리수 이다 - 전체 자리수를 초과할 경우 입력 거부되지만 소수점 이하 자리수가 초과되면 반올림되어 입력 된다 * n:정수만 입력하고 p는 입력 안해도 됨 3. DATE - 날짜 타입, 출력이나 입력 형식과 무관하게 YYYY/MM/DD:HH24:MI:SS 형태로 저장됨 * 기원전 4712년 1월 1일 - 서기 9999년 12월 31일까지만 사용 가능 |
테이블 생성 관련 명령어
테이블 목록 확인 하는 명령어  SQL> SELECT * FROM tab; ---> 현재 접속한 계정이 가지고 있는 테이블 목록을 한눈에 확인할 때 사용  SELECT table_name FROM user_tables; ---> 내가 만든 테이블들의 공식 명부(user_tables)에서 이름(table_name)만 쏙쏙 뽑아서 보여줘 라는 뜻 테이블 컬럼의 구성 확인하는 명령어 1.  SET LINESIZE 200 COLUMN Name FORMAT A20 COLUMN Null? FORMAT A10 COLUMN Type FORMAT A20 DESC EMP; 2.  2. COLUMN TABLE_NAME FORMAT A15 COLUMN COLUMN_NAME FORMAT A15 COLUMN DATA_TYPE FORMAT A10 SET LINESIZE 200 SQL> SELECT table_name, column_name, data_type, data_length 2 FROM user_tab_columns 3 [WHERE table_name = 'EMP']; |
테이블 만들어보기
| 화면 출력 설정 SET LINESIZE 200 COLUMN TABLE_NAME FORMAT A20; 명령어 CREATE TABLE board ( no NUMBER, name VARCHAR2(50), sub VARCHAR2(100), content VARCHAR2(4000), hdate DATE DEFAULT SYSDATE ); SELECT * FROM tab; SELECT table_name FROM user_tables WHERE table_name = 'BOARD'; DESC board;  SET LINESIZE 200; -- 화면 가로 길이를 늘려 출력 깨짐 방지 COLUMN table_name FORMAT A20; -- 테이블 이름 칸 너비를 20자로 고정 CREATE TABLE board ( -- 'board'라는 이름의 테이블 생성 시작 no NUMBER, -- 'no' 칸을 숫자 타입으로 생성 name VARCHAR2(50), -- 'name' 칸을 최대 50바이트 문자 타입으로 생성 sub VARCHAR2(100), -- 'sub' 칸을 최대 100바이트 문자 타입으로 생성 content VARCHAR2(4000), -- 'content' 칸을 최대 4000바이트 문자 타입으로 생성 hdate DATE DEFAULT SYSDATE -- 'hdate' 칸을 날짜 타입으로 생성 (기본값은 행을 입력할때 현재 시간, 날짜가 자동으로 입력되도록 한다라는 뜻) ); -- 테이블 생성 종료 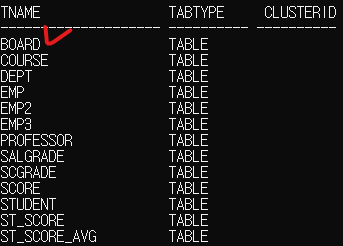 SELECT * FROM tab; -- 전체 목록에서 생성 여부 확인  SQL> SELECT table_name FROM user_tables 2 WHERE table_name = 'BOARD'; -- 'BOARD' 이름만 정확히 조회 |
테이블 안의 행 입력하고 확인하기
| 화면 출력 SET LINESIZE 150; SET PAGESIZE 100; COLUMN TABLE_NAME FORMAT A15; COLUMN COLUMN_NAME FORMAT A15; COLUMN DATA_TYPE FORMAT A15; COLUMN NAME FORMAT A15; COLUMN SUB FORMAT A20; COLUMN CONTENT FORMAT A30; 명령어 DESC board; SELECT table_name, column_name, data_type, data_length FROM user_tab_columns WHERE table_name = 'BOARD'; INSERT INTO board (no) VALUES (1); COMMIT; SELECT * FROM board; 명령어 해석 DESC board; -- board 테이블의 칸 이름과 데이터 타입을 간단히 확인 SELECT table_name, column_name, data_type, data_length FROM user_tab_columns -- user_tab_columns 명부에서 board 테이블의 설계도(이름, 타입, 길이 등)를 상세히 조회 WHERE table_name = 'BOARD'; -- * 테이블 이름은 반드시 대문자 'BOARD'로 적어야 검색이 됨 INSERT INTO board (no) VALUES (1); -- board 테이블의 'no' 칸에 숫자 1을 집어넣는다 COMMIT; -- 입력한 데이터(1번)를 데이터베이스에 영구적으로 저장(확정)함  SELECT * FROM board; -- board 테이블에 들어있는 모든 데이터(*)를 꺼내서 화면에 보여준다 |
문자 타입 데이터
| 문자와 숫자 구별 문자 - 주민번호, 군번, 숫자만으로 구성된 학번: 문자 * 각각의 숫자가 각각 의미를 가진다면 문자라고 보면 됨 * 연산 가능성이 없음 숫자 - 금액 * 연산 가능성이 있음 * NULL에 주의 VACHAR, VARCHAR2 - 같은 데이터 타입 CHAR, VARCHAR2 - 주로 VARCHAR2를 많이 쓴다 |
CHAR, VARCHAR2의 비교
동일한 값이 입력된 두 컬럼이 데이터 타입에 따라 다르게 인식됨을 확인 한다 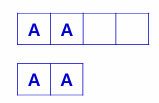 명령어 SQL> CREATE TABLE comp( 2 co1 CHAR(4), 3 4 co2 VARCHAR2(4) ); SQL> INSERT INTO comp VALUES ('AA','AA'); A A SQL> SELECT LENGTHB(co1), LENGTHB(co2) FROM comp; SQL> SELECT * FROM comp WHERE co1='AA'; A A SQL> SELECT * FROM comp WHERE co2='AA'; SQL> SELECT * FROM comp WHERE co1=co2; * 이 명령어는 찾을 수 없음, 왜냐하면 둘의 크기는 같지 않기 때문임 명령어 설명 CREATE TABLE comp( --- 1. 테이블 생성: 고정 길이(CHAR)와 가변 길이(VARCHAR2) 컬럼을 각각 만듦 co1 CHAR(4), -- 고정 길이: 무조건 4바이트 공간을 차지함 co2 VARCHAR2(4) -- 가변 길이: 입력한 데이터 크기만큼만 공간을 사용함 ); INSERT INTO comp VALUES ('AA', 'AA'); -- 2. 데이터 입력: 두 컬럼에 똑같이 'AA'라는 두 글자를 넣음 - INSERT INTO: 데이터를 집어넣겠다라는 선언임 - COMP: 데이터를 넣을 대상 테이블의 이름임 - VALUES: 실제로 들어갈 값들은 이것이라라고 알려주는 키워드 SELECT LENGTHB(co1), LENGTHB(co2) FROM comp; -- 3. 바이트 크기 확인: 실제 저장된 데이터의 크기를 숫자로 보여줌 -- 결과: co1은 4 (AA 뒤에 공백 2칸 추가됨), co2는 2 (AA만 저장됨) 4. 조건 검색 (개별): 각각 'AA'와 같은지 확인 SELECT * FROM comp WHERE co1='AA'; -- 결과 나옴 (오라클이 비교 시 공백을 무시함) SELECT * FROM comp WHERE co2='AA'; -- 결과 나옴 5. 조건 검색 (컬럼끼리 비교): 두 컬럼의 값이 같은지 확인 SELECT * FROM comp WHERE co1=co2; -- 결과: 데이터 없음 (공백이 포함된 'AA '와 공백 없는 'AA'는 다른 값으로 취급함) |
날짜 타입 컬럼 검색
| 명령어 SQL> CREATE TABLE hd ( 2 no NUMBER, 3 4 hdate DATE ); SQL> INSERT INTO hd VALUES (1, sysdate); SQL> SELECT * FROM hd; SQL> SELECT * FROM hd WHERE hdate = '2021/10/02'; SQL> SELECT no, TO_CHAR(hdate,'YYYY/MM/DD:HH24:MI:SS') FROM hd; SQL> SELECT * FROM hd 2 WHERE hdate BETWEEN '2021/10/02' AND '2021/10/03'; 명령어 설명 1. 테이블 생성 CREATE TABLE hd ( no NUMBER, -- 번호 저장 hdate DATE -- 날짜와 시간 저장 ); 2. 데이터 입력 (현재 날짜와 시간 입력) INSERT INTO hd VALUES (1, sysdate); * 오라클에서 SYSDATE는 오늘이 아니라 지금 이순간(초 단위)을 저장하기 때문에, 날짜만 검색하면 시간이 달라서 안 찾아지는것임 그래서 시간을 절삭해주는 TRUNC 함수를 써야함 1: no(번호) 의 숫자 sysdate: 날짜와시간 출력예시 ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ no (번호) hdate (날짜와 시간) 1 2026/02/09 15:00:00 ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ 2-1 명령어 수정 INSERT INTO hd VALUES (1, TRUNC(sysdate)); 3. 전체 조회 (기본 설정에 따라 시간은 안 보일 수 있음) SELECT * FROM hd; 4. 특정 날짜 검색 SELECT * FROM hd WHERE hdate = '2021/10/02'; -- '2021/10/02 00:00:00'인 데이터만 찾으라는 뜻 5. 시간 정보까지 상세 조회 SELECT no, TO_CHAR(hdate,'YYYY/MM/DD:HH24:MI:SS') FROM hd; -- 해석: hdate에 저장된 시, 분, 초까지 문자열로 바꿔서 눈으로 확인함 6. 범위 검색 SELECT * FROM hd WHERE hdate BETWEEN '2021/10/02' AND '2021/10/03'; -- 해석: 10월 2일 0시 0분 0초부터 10월 3일 0시 0분 0초 사이의 데이터를 찾음 * 4,5,6 번은 sysdate 로 명령어 입력 시 검색이 안될때 상세 데이터를 찾는 명령어임 |
한눈에 보는 비교 표
| 구분 | 명령어 | 저장되는 값 (예시) | 날짜 검색(=) 가능 여부 |
| 안 썼을 때 | sysdate | 2026-02-09 14:30:05 | 불가능 (시간이 달라서) |
| 썼을 때 | TRUNC(sysdate) | 2026-02-09 00:00:00 | 가능 (시간이 0으로 같아서) |
삭제 테이블 복구
| 1. 생성 및 확인: CREATE TABLE test (id NEMBER); 후 SELECT * FROM tab; 으로 확인 2. 삭제: DROP TABLE test; 실행 (이후 tab 조회시 BIN$ 로 시작하는 쓰레기통 이름만 보임 3. 휴지통 조회: 출력 설정: COL object_name FORMAT a3, COL original_name a20 * ORIGINAL_NAME (원래 이름:test) OBJECT_NAME (쓰레기통 이름:TESTBIN$j4u5lR7+S+...) 4. 복구: FLASHBACK TABLE test TO BEFORE DROP; 명렁어로 되살리기 5. 최종 확인: SELECT * FROM tab; 으로 테이블이 돌아왔는지 확인 |
'Infra & Security Eng > Database Engineering' 카테고리의 다른 글
| SQL 기존 테이블 삭제, 새 테이블 생성 관련 (실습) (@sc.sql) (0) | 2026.02.09 |
|---|---|
| 제약조건 특징, 종류, 검색, PK와 FK의 특징, 무결성 통제, 명령어 개념까지 (0) | 2026.02.09 |
| DML, TCL 개념, 핵심 명령어, 핵심 문제 (0) | 2026.02.06 |
| 그룹 함수와 GROUP BY 개념, 사용하는 이유, 종류, 문제 (0) | 2026.02.05 |
| 단일 행 함수 변환 함수 실습 (0) | 2026.02.04 |



