반응형
1. 인덱스의 정의
| 인덱스는 데이터베이스 안에 있는 데이터를 빨리 찾기 위해 따로 만들어 놓은 '주소록' 같은 데이터 공간 이다 인덱스는 특정 데이터가 **어디(위치 정보)**에 있는지 미리 정리해 두어 검색 시간을 줄여준다 |
2. 인덱스 종류와 특징
| 1. 인덱스의 종류 - 값의 성격에 따라 1) 고유 인덱스(Unique Index): 중복 값 불가능 (NULL도 허용하지 않는 것이 일반적) 2) 비 고유 인덱스(Non-unique): 중복 값 가능 - 물리 구조에 따라 B-Tree: 가장 흔히 사용, 위로 뻥어 나가는 트리 구조임, 즉 트리가 위로 올라가는 구조 Bitmap: 테이블 분석 작업에 주로 사용 2. 인덱스 생성(자동 vs 수동) 자동 생성: PK(기본키), UK(고유키) 지정 시 자동으로 Unique Index가 생성됨 수동 생성: CREATE INDEX 명령어로 직접 생성. 보통 Non-unique Index가 생성됨 * FK(외래키) 인덱스: 외래키 컬럼에는 반드시 인덱스를 생성할 것. 인덱스 이름을 외래키와 동일하게 지어 혼동을 방지함(상황에 따라 판단하여 생성) 3. 삭제와 확인 삭제: 직접 생성한 것만 삭제 가능. PK에 의해 자동 생성된 인덱스는 직접 삭제 불가함 확인: 인덱스 생 시 사용한 수식(column_expression)을 통해 인덱스 구성을 확인할 수 있음 |
3. 인덱스 생성과 삭제하기
| 인덱스 생성 CREATE INDEX 인덱스 ON 테이블 (컬럼 | 함수 | 수식); 인덱스 삭제 DROP INDEX 인덱스; 인덱스 생성 예시 CREATE INDEX idx_student_name -- 'idx_student_name'이라는 이름으로 인덱스를 만들어라 ON student (name); -- 'student' 테이블의 'name' 컬럼을 기준으로 |
4. 인덱스 생성 한것 확인 하기
| SELECT c.index_name, -- 1. 인덱스의 이름을 보여줘 c.column_name, -- 2. 어떤 컬럼으로 만들었는지 보여줘 c.column_position, -- 3. 컬럼이 여러 개라면 몇 번째 순서인지 보여줘 i.uniqueness -- 4. 중복이 안 되는지(UNIQUE) 되는지(NONUNIQUE) 보여줘 FROM user_indexes i, -- '인덱스 요약 정보'가 담긴 i 장부와 user_ind_columns c -- '인덱스 상세 컬럼'이 담긴 c 장부를 가져와서 WHERE c.index_name = i.index_name; -- 두 장부에서 '이름이 똑같은 것'끼리 합쳐서 보여줘 * WHERE절: 두 개의 다른 장부에서 같은 데이터를 찾아 하나로 합치기 위해" 중복된 값을 가진 컬럼을 연결 고리로 써준 것 |
* 인덱스 이름과 상세 컬럼 예시
| 구분 | 인덱스 이름 (INDEX_NAME) | 상세 컬럼 (COLUMN_NAME) | 비고 |
| 수동 생성 | IDX_STUDENT_NAME | NAME | 이름으로 빨리 찾으려고 직접 만든 것 |
| 수동 생성 | IDX_SCORE_SNO | SNO | 학번(SNO)으로 점수를 빨리 찾으려고 만든 것 |
| 자동 생성 | SYS_C0011042 | SNO | Primary Key 설정 시 컴퓨터가 자동 생성 |
| 자동 생성 | SYS_C0011045 | Unique Key 설정 시 컴퓨터가 자동 생성 |
외래키 내용 추가 후 인덱스 확인하기 (school0211constraints.sql파일)
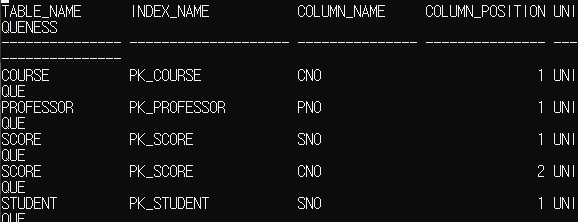
| school0211constraints.sql 파일에 있던 기존 제약 조건 ALTER TABLE dept ADD CONSTRAINT pk_dept PRIMARY KEY (dno); ALTER TABLE emp ADD CONSTRAINT pk_emp PRIMARY KEY (eno); ALTER TABLE salgrade ADD CONSTRAINT pk_salgrade PRIMARY KEY (grade); ALTER TABLE student ADD CONSTRAINT pk_student PRIMARY KEY (sno); ALTER TABLE professor ADD CONSTRAINT pk_professor PRIMARY KEY (pno); ALTER TABLE course ADD CONSTRAINT pk_course PRIMARY KEY (cno); ALTER TABLE score ADD CONSTRAINT pk_score PRIMARY KEY (sno, cno); ALTER TABLE emp ADD CONSTRAINT fk_emp_dno FOREIGN KEY (dno) REFERENCES dept (dno); ALTER TABLE emp ADD CONSTRAINT fk_emp_mgr FOREIGN KEY (mgr) REFERENCES emp (eno); ALTER TABLE course ADD CONSTRAINT fk_course_pno FOREIGN KEY (pno) REFERENCES professor (pno); ALTER TABLE score ADD CONSTRAINT fk_score_sno FOREIGN KEY (sno) REFERENCES student (sno); ALTER TABLE score ADD CONSTRAINT fk_score_cno FOREIGN KEY (cno) REFERENCES course (cno); 외래키 내용 추가 CREATE INDEX fk_emp_dno ON emp(dno); CREATE INDEX fk_emp_mgr ON emp(mgr); CREATE INDEX fk_course_pno ON course(pno); CREATE INDEX fk_score_sno ON score(sno); ---> 기존 PK 인덱스가 자동으로 생성되어 있으므로 내용 추가 안 해도 되긴 하지만 완벽성을 위해 넣어줌 CREATE INDEX fk_score_cno ON score(cno); 외래키 내용 추가한 것 인덱스 확인하기 확인 명령어 SELECT i.table_name, i.index_name, c.column_name, c.column_position, i.uniqueness FROM user_indexes i, user_ind_columns c WHERE c.index_name = i.index_name AND i.table_name IN ('STUDENT', 'PROFESSOR', 'COURSE', 'SCORE') ORDER BY i.table_name, i.index_name, c.column_position; 출력 내용 |
* 테이블별 외래키 지정 이유
| 테이블 | 외래키 컬럼 | 누구랑 연결되나? | 왜 연결하나? (이유) |
| EMP | dno | DEPT(부서) | 이 직원이 어느 부서 소속인지 알기 위해서 |
| EMP | mgr | EMP(사원) | 이 직원의 상사가 누구인지 사원 목록에서 찾으려고 |
| COURSE | pno | PROFESSOR(교수) | 이 수업을 가르치는 교수님이 누구인지 알기 위해서 |
| SCORE | sno | STUDENT(학생) | 이 점수가 어떤 학생의 점수인지 알기 위해서 |
| SCORE | cno | COURSE(과목) | 이 점수가 어떤 과목의 점수인지 알기 위해서 |
| 외래키(FK) 지정의 기술적 이유: 참조 무결성 유지 외래키는 **부모 데이터가 없는 자식 데이터(고아 레코드)**가 생기는 것을 물리적으로 차단하여 데이터의 신뢰도를 100%로 유지하는 장치다. 1. EMP (사원) → DEPT (부서) 구조: EMP.dno(자식)가 DEPT.dno(부모)를 참조한다. 정확한 이유: 사원 테이블의 부서 번호(dno)는 반드시 부서 테이블에 존재하는 값이어야만 한다. 효과: 존재하지 않는 부서 번호가 사원 정보에 입력되는 입력 오류를 차단하고, 사원이 소속된 부서가 갑자기 삭제되어 소속 정보가 공중에 뜨는 현상을 방지한다. 2. EMP (사원) → EMP (사원) [Self-Reference] 구조: EMP.mgr(자식 컬럼)이 동일 테이블의 EMP.eno(부모 컬럼)를 참조한다. 정확한 이유: 관리자(mgr)도 결국 사원이다. 따라서 관리자 번호는 반드시 사원 번호(eno) 목록에 이미 등록된 값이어야 한다. 효과: 조직도의 계층 구조(Hierarchy)를 데이터적으로 검증한다. 퇴사하여 삭제된 사원 번호를 누군가의 상사로 지정하는 논리적 모순을 막는다. 3. COURSE (과목) → PROFESSOR (교수) 구조: COURSE.pno(자식)가 PROFESSOR.pno(부모)를 참조한다. 정확한 이유: 과목 테이블의 담당 교수 번호는 반드시 교수 테이블의 기본키(PK)와 일치해야 한다. 효과: 데이터의 참조 일관성을 유지한다. 교수가 퇴직 등으로 삭제될 때, 그 교수가 담당하던 과목 데이터를 어떻게 처리할지(함께 삭제할지, 유지할지) DB 수준에서 강제한다. 4. SCORE (점수) → STUDENT (학생) & COURSE (과목) 구조: SCORE 테이블은 STUDENT와 COURSE라는 두 개의 부모를 가진다. 정확한 이유: 점수는 단독으로 존재할 수 없는 의존적 데이터다. 반드시 '등록된 학생'과 '개설된 과목'이라는 두 조건이 모두 충족되어야만 입력을 허용한다. 효과: 다대다(N:M) 관계의 정합성을 보장한다. 학생이 자퇴하거나 과목이 폐강되었을 때, 주인 없는 점수 데이터가 남아 데이터베이스를 오염시키는 것을 원천 봉쇄한다. |
외래키 내용 추가 후 인덱스 확인하기 (salesconstraints.sql파일)
| salesconstraints.sql 파일에 있던 기존 제약 조건 ALTER TABLE "제품" ADD CONSTRAINT "제품_제품번호_PK" PRIMARY KEY ("제품번호"); ALTER TABLE "제품" ADD CONSTRAINT "제품_제품명_UK" UNIQUE ("제품명"); ALTER TABLE "제품" ADD CONSTRAINT "제품_제품단가_CK" CHECK ("제품단가" > 0); ALTER TABLE "판매전표" MODIFY "판매일자" CONSTRAINT "판매전표_판매일자_NN" NOT NULL; ALTER TABLE "판매전표" MODIFY "고객명" CONSTRAINT "판매전표_고객명_NN" NOT NULL; ALTER TABLE "판매전표" MODIFY "총액" CONSTRAINT "판매전표_총액_NN" NOT NULL; ALTER TABLE "판매전표" ADD CONSTRAINT "판매전표_전표번호_PK" PRIMARY KEY ("전표번호"); ALTER TABLE "판매전표" ADD CONSTRAINT "판매전표_총액_CK" CHECK ("총액" > 0); ALTER TABLE "전표상세" MODIFY "수량" CONSTRAINT "전표상세_수량_NN" NOT NULL; ALTER TABLE "전표상세" MODIFY "단가" CONSTRAINT "전표상세_단가_NN" NOT NULL; ALTER TABLE "전표상세" MODIFY "금액" CONSTRAINT "전표상세_금액_NN" NOT NULL; ALTER TABLE "전표상세" ADD CONSTRAINT "전표상세_PK" PRIMARY KEY ("전표번호", "제품번호"); ALTER TABLE "전표상세" ADD CONSTRAINT "전표상세_전표번호_FK" FOREIGN KEY ("전표번호") REFERENCES "판매전표" ("전표번호"); ALTER TABLE "전표상세" ADD CONSTRAINT "전표상세_제품번호_FK" FOREIGN KEY ("제품번호") REFERENCES "제품" ("제품번호"); ALTER TABLE "전표상세" ADD CONSTRAINT "전표상세_금액_CK" CHECK ("금액" > 0); 외래키 내용 추가 CREATE INDEX "전표상세_제품번호_FK" ON "전표상세" ("제품번호"); 외래키 내용 추가한 것 인덱스 확인하기 확인 명령어 SELECT c.index_name, c.column_name, c.column_position FROM user_indexes i, user_ind_columns c WHERE c.icndex_name = i.index_name AND c.table_name = '전표상세' ORDER BY c.index_name, c.column_position; 출력 내용  |
| 추가 설명 1. SELECT c.index_name, c.column_name, c.column_position 설명: 우리가 보고 싶은 정보 세 가지(인덱스 이름, 컬럼 이름, 컬럼 순서)를 선택하는 명령이다. 화면에 이 세 가지 항목만 결과로 나타난다 2. FROM user_indexes i, user_ind_columns c 설명: 데이터를 꺼내올 장소를 정합니다. user_indexes라는 정보 주머니와 user_ind_columns라는 정보 주머니 두 개를 사용하겠다는 뜻이다. 뒤에 붙은 i와 c는 주머니 이름이 길어서 붙여준 짧은 별명이다 3. WHERE c.index_name = i.index_name 설명: 두 주머니에 들어있는 정보 중에서 서로 이름이 같은 인덱스끼리 짝을 맞춰주는 작업이다. 엉뚱한 정보끼리 섞이지 않게 연결해 준다 4. AND c.table_name = '전표상세' 설명: 많은 데이터 중에서 우리가 진짜 궁금한 '전표상세'라는 테이블에 대한 정보만 골라내는 필터이다 5. ORDER BY c.index_name, c.column_position; 설명: 나온 결과를 순서대로 정리한다.먼저 인덱스 이름별로 모으고, 그 안에서 컬럼 번호가 1번, 2번, 3번... 순서대로 보이게 정렬한다 |
| 참고사항 SQL> DROP INDEX student_sno_pk; Primary Key에 의해 자동생성 된것이므로 삭제가 안됨 그래서 disable로 비활성화해줌 --> enable 하면 다시 살아남 |
| 참고사항 ROWID: 행의 물리적인 위치 table 전체 크기: 10000행 SELECT행: 1행 full table scan: 10000행:10000초 1행 읽는데 1초 걸림 * 테이블이 작으면 full table scan이 편함 index scan: 1행 읽는데 10초 걸림 (테이블이 커지면 index scan이 좋음) |
'Infra & Security Eng > Database Engineering' 카테고리의 다른 글
| 인라인 뷰 Top-N 분석과 RANK 개념과 실습 (0) | 2026.02.12 |
|---|---|
| SQL 뷰 인라인뷰 개념,특징, 실제 문제 (0) | 2026.02.12 |
| SQL 테이블 지우고 명령어로 확인하는 프로세스 (0) | 2026.02.11 |
| 제약 조건 관리 추가 삭제와 비활성화 명령어와 해설 (0) | 2026.02.10 |
| [Oracle] 제약 조건(UK, CHECK, NOT NULL) 완벽 정리와 실습 (0) | 2026.02.10 |



